
Witam w ostatniej części cyklu, w którym próbuję zachęcić do dołączenia do społeczności tworzącej Wolne i Otwarte Oprogramowanie. W pierwszym odcinku opowiedziałem czym jest WiOO i pokazałem, jak można się zaangażować jako osoba programująca, tworząca dokumentację, zgłaszająca błędy i podsuwająca pomysły na nowe funkcjonalności. Druga część była poświęcona testowaniu aplikacji w czasie ich powstawania, pomaganiu innym użytkownikom oraz wspieraniu osób tworzących FOSS, a tym razem opowiem o tłumaczeniu oprogramowania.
Spis treści
- Wprowadzenie
- Tłumaczenie przy użyciu webinterfejsów
- Przez ręczną edycję plików
- W polskim zespole GNOME
– ![]() –
–
Wprowadzenie
W końcu przyszła pora na mój ulubiony sposób angażowania się w WiOO, czyli tłumaczenie programów, tak by jak najwięcej osób mogło z nich korzystać.
W tej chwili mam na koncie tłumaczenie na polski m.in.:
- klienta Fediwersum Tuba,
- androidowych klientów fedi Pixelix oraz Pachli,
- edytora Markdown Scratchmark,
- klienta Tidala Tonearm,
- strony Join the Fediverse,
- aplikacji pogody Mousam,
- wtyczki dla WordPressa Embed Consent.
Przy okazji nauczyłem się zupełnie nowych rzeczy. Dzięki Tubie i Pixelix poznałem interfejsy do tłumaczenia Weblate i Crowdin, dla Join the Fediverse dowiedziałem się jak forkować repozytorium i tworzyć merge request ze zmianami, a Mousam zawdzięczam poznanie tworzenia plików tłumaczenia przy użyciu narzędzi gettext. Dla kogoś innego to może być masa roboty, dla mnie zdobywanie nowych umiejętności i doświadczeń jest jedną z zalet angażowania się w WiOO.
Na podstawie powyższej listy mogliście się zorientować, że samo przetłumaczenie komunikatów to nie wszystko, bo trzeba jeszcze nasze tłumaczenie przekazać osobom tworzącym program, aby mogły je do niego włączyć. Można to zrobić na różne sposoby, w zależności od mechanizmów, które oferuje konkretny projekt. Żeby sprawdzić, który jest dostępny w danym przypadku, trzeba zacząć od zajrzenia na stronę programu.
– ![]() –
–
Tłumaczenie przy użyciu webinterfejsów
Spora część aplikacji, które są rozwijane już dłuższy czas, dorobiła się mechanizmów ułatwiających tłumaczenie. Najczęściej są to wyspecjalizowane serwisy, z których najpopularniejsze są Weblate i Crowdin. Jeżeli na stronie projektu znajdziecie wzmiankę o którymś z nich, wasza praca przy tłumaczeniu będzie prosta i wygodna.
Zabawa zaczyna się od założenia konta w używanym przez dany program serwisie, po czym przechodzimy do wybranego projektu. Na liście dostępnych języków szukamy tego, na który chcemy tłumaczyć. Jeżeli już jest, możemy od razu przejść do tłumaczenia, w przeciwnym przypadku, trzeba najpierw do dodać.
W Weblate robi się to kliknięciem mało rzucającego się w oczy plusa, znajdującego się po lewej stronie nad ikonkami ołówka przy liście dostępnych tłumaczeń. Potem wybieramy język, na który chcemy tłumaczyć i klikamy „Rozpocznij nowe tłumaczenie”.
Na Crowdin trzeba kliknąć „Poproś o nowy język” i poza wyborem języka dodać wiadomość dla osób zarządzających projektem. Nie miałem okazji tego robić, ale zakładam, że taka prośba musi być ręcznie zatwierdzona, więc być może trzeba będzie trochę poczekać.
Gdy mamy już konto i wybrany język jest dostępny na liście tłumaczeń, możemy przystąpić do pracy, chyba że trafiliśmy na rzadki wypadek, w którym osoba rozwijająca oprogramowanie wymaga zaakceptowania „Contributor Licence Agreement”. Do tej pory przydarzyło mi się to tylko raz, przy tłumaczeniu Pachli.
Teraz już naprawdę możemy zabrać się za tłumaczenie. W większości małych i średnich programów całość tekstów do przetłumaczenia (nazywanych wiadomościami lub ciągami) jest zebrana w jednym module. Niektóre aplikacje, takie jak Pachli właśnie, rozbijają je na kilka różnych. Takie rozwiązanie ma swoje wady i zalety. Niektórym pewnie łatwiej ogarnąć garść ciągów na raz zamiast długiego zestawu, ja wolę raczej mieć wszystko w jednym miejscu.
No dobrze, mamy konto, wybrany język jest dostępny, zaakceptowaliśmy licencję i wklikaliśmy się w moduł do tłumaczenia. Co dalej? Zostało nam żmudne wypełnianie formularzy.
– ![]() –
–
Weblate
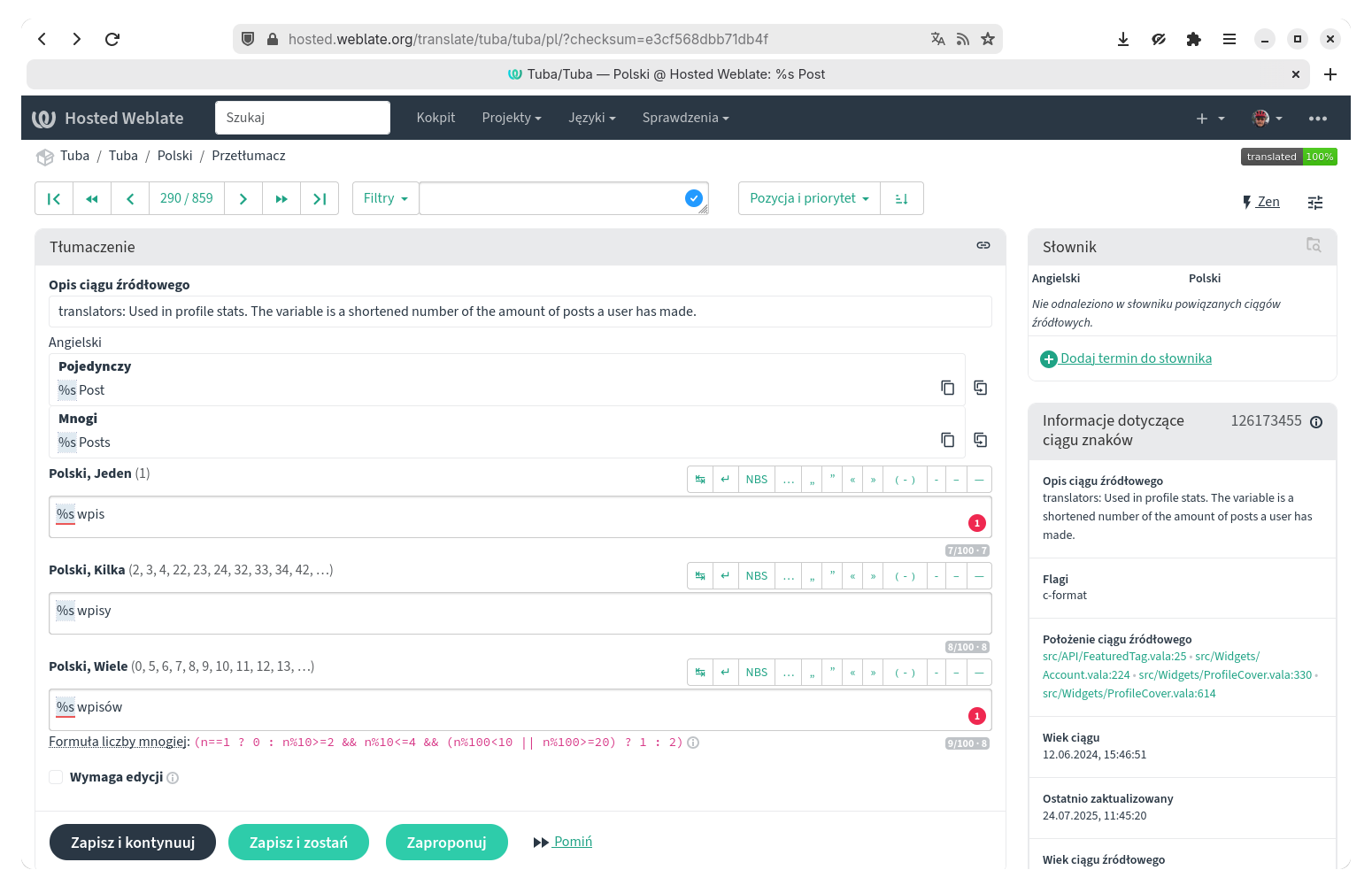
Powyżej znajduje się zrzut interfejsu Weblate z otwartym polskim tłumaczeniem Tuby. Pasek nad boksem „Tłumaczenie” pozwala na nawigację po ciągach i pokazuje aktualną pozycję na tle całości. Pole obok umożliwia wyszukiwanie ciągów spełniających określone wymagania (nieprzetłumaczone, oznaczone do dalszej edycji, z komentarzami itp.), a ostatnie służy do sortowania wiadomości do przetłumaczenia, dzięki czemu możemy np. szybko dotrzeć do ciągów ostatnio dodanych do aplikacji.
Główną część okna zajmuje miejsce na właściwe tłumaczenie. Pierwsze od góry jest pole z opisem ciągu dodawanym przez osoby tworzące aplikacje. Taki opis jest bardzo pomocny, zwłaszcza gdy trudno na podstawie ciągu źródłowego zorientować się, jaki jest kontekst jego wystąpienia, lub gdy w wiadomości występują jakieś zmienne (tutaj to %s oznaczające ilość wpisów).
Szkoda, że stosowanie opisów nie jest powszechniejsze, bo często zdarza się, że trudno zorientować się, jak najlepiej przetłumaczyć komunikat, bo np. w aplikacji oryginalny zwrot występuje w kilku miejscach, a każde wystąpienie po polsku będzie brzmiało inaczej. Tutaj może pomóc znajdująca się w prawej kolumnie informacja „Położenie ciągu źródłowego”, dzięki której możemy jednym kliknięciem otworzyć plik źródłowy i zobaczyć, gdzie znajduje się ten ciąg. Niestety, wymaga to chociaż podstawowej umiejętności czytania kodu.
Prawie zawsze w czasie tłumaczenia poza oknem, w którym pracuję, mam otwartą też aplikację, nad która pracuję, oraz repozytorium z kodem źródłowym, żeby móc odnaleźć kontekst, w którym występuje przekładany akurat tekst.
Pod opisem mamy oryginalną wiadomość. Tu wybrałem dla was rzecz trochę rzadszą, bo mamy do czynienia z rzeczownikiem z liczbą pojedynczą i mnogą. Jak widzicie, w angielskim to są dwa pola, u nas już trzy, ponieważ „posts” będziemy tłumaczyć inaczej w zależności od tego, czy to są „trzy wpisy”, czy „pięć wpisów”. Czerwone magiczne zaklęcie pod polami na tłumaczenie to formuła definiująca, dla jakich liczb występują odmienne formy liczby mnogiej.
Zazwyczaj jednak mamy do czynienia z prostą wersją jeden ciąg źródłowy = jeden ciąg przetłumaczony, ale wolałem wyjaśnić sprawę form liczby mnogiej, żebyście się nie dziwili, o co tu chodzi.
Pod polami na tłumaczenie znajduje się pole „Wymaga edycji”. Można go użyć, gdy np. nie jesteśmy pewni tłumaczenia i będziemy chcieli do niego wrócić.
Dwa z trzech przycisków poniżej są dość oczywiste: „Zapisz i kontynuuj” zapisze nasze tłumaczenie i przejdzie do następnego ciągu, „Zapisz i zostań” również zapisze, ale pozostanie w miejscu. Co robi „Zaproponuj”? Jeżeli chcemy poprawić czyjeś tłumaczenie, ale bez wcinania się w pracę tej osoby, możemy zaproponować swoją wersję. Taką sugestię osoba tłumacząca będzie potem mogła zaakceptować lub odrzucić, czasem też dodając komentarz tłumaczący decyzję.
Pod tłumaczeniem znajduje się pięć kart z przydatnymi narzędziami. Pierwsze z nich to „Ciągi sąsiadujące”, pozwalające czasem na umieszczenie wiadomości w kontekście lub przypomnienie sobie tłumaczenia zbliżonych tekstów. „Komentarze” to po prostu miejsce na skomentowanie tłumaczenia, z możliwością oznaczania zarówno innych tłumaczy, jak i osób tworzących aplikację. „Automatyczne sugestie” to tłumaczenia pochodzące z serwisu LibreTranslate oraz podsuwane na podstawie pamięci tłumaczeń, w której wyszukiwane są tłumaczenia podobnych ciągów. W „Innych językach” możemy sprawdzić, jak ten ciąg był przełożony w innych wersjach językowych, co jest przydatne raczej tylko dla osób posługujących się wieloma językami, a karta „Historia” pozwala na prześledzenie zmian w tłumaczeniu: kto, jak i kiedy przełożył ciąg.
W kolumnie po prawej, poza wspomnianym już odnośnikiem do pliku źródłowego, znajdują się informacje dotyczące ciągu, w tym data powstania i ostatniej aktualizacji. Powyżej znajduje się funkcja, której jeszcze nigdy nie użyłem, czyli „Słownik”, który pozwala na zapisanie własnych terminów, co pewnie jest bardzo przydatne zwłaszcza przy tłumaczeniu aplikacji używającej jakiejś zaawansowanej terminologii, gdy musimy pamiętać specjalistyczne słownictwo.
– ![]() –
–
Crowdin
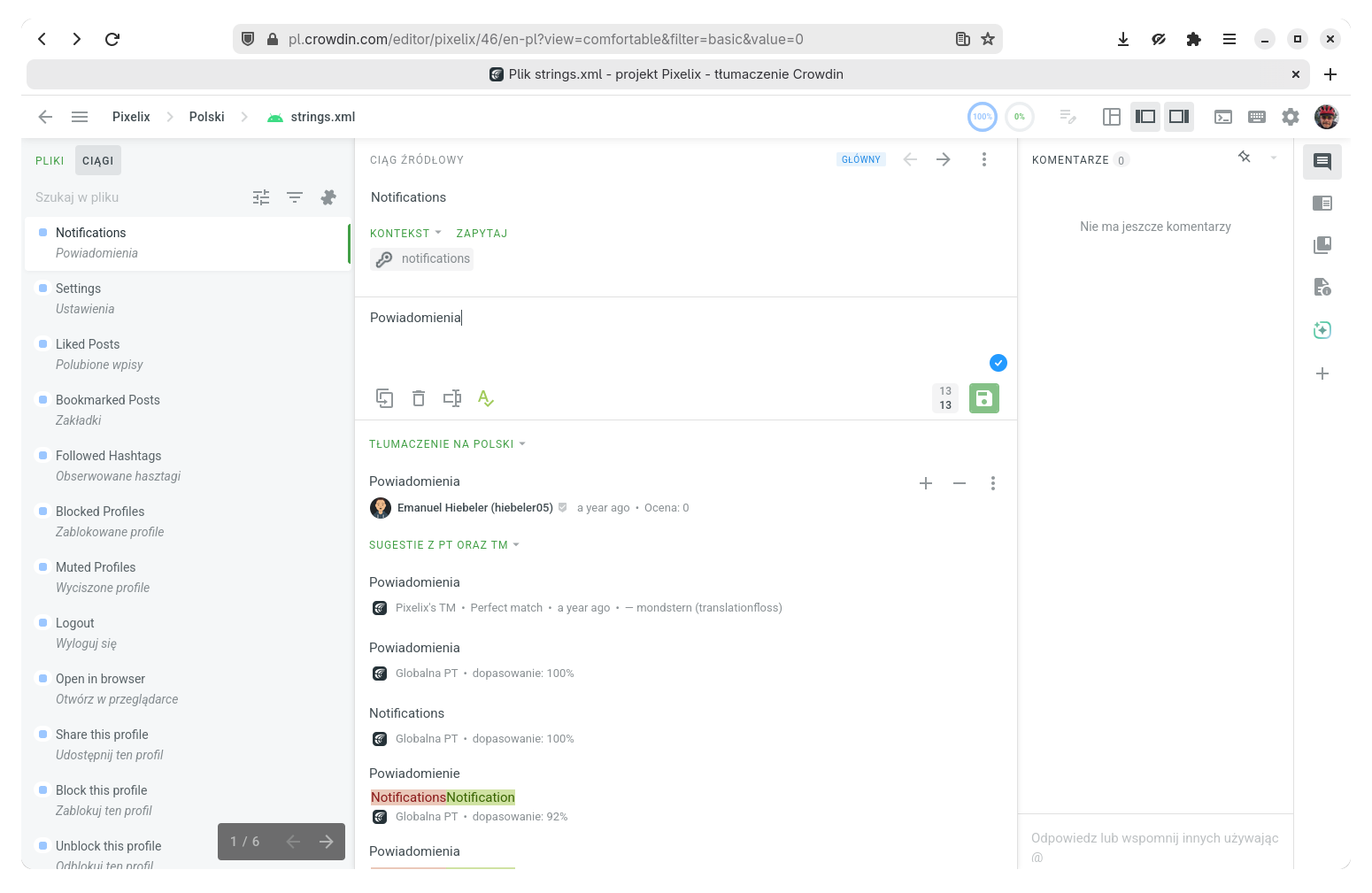
Muszę przyznać, że nie jestem fanem Crowdin i jego interfejs uważam za mniej wygodny niż Weblate. Jak widać na zrzucie powyżej, bardzo różni się od tego drugiego serwisu, ale po przyjrzeniu się rozpoznacie podobne elementy. Lewa strona to przeglądarka ciągów (można przełączyć ją na przeglądanie plików) z opcjami ich filtrowania i sortowania.
Część środkowa to ciąg źródłowy z kontekstem (i możliwością zapytania o niego) oraz miejsce na tłumaczenie. Poniżej znajdują się informacje o tłumaczeniu oraz sugestie z pamięci tłumaczeń oraz tłumaczenia maszynowego Crowdin Translate. Jest też możliwość podejrzenia wersji w innych językach.
Prawa strona to miejsce na komentarze tłumaczy, w tym przypadku proszących o zmianę, gdyż forma, w jakiej ciąg występuje w aplikacji, nie działa w ich językach.
Zamiast komentarzy można włączyć panel przeszukiwania pamięci tłumaczeń, słownika i kontekstu, oraz asystenta AI (ha, tfu!).
– ![]() –
–
Tłumaczenie poprzez edycję plików
Tu już mamy do czynienia z trochę bardziej zaawansowanym tematem, bo takie tłumaczenie wymaga znajomości podstaw obsługi repozytoriów git i gotowości do posługiwania się trybem tekstowym. Konieczność sięgnięcia po ten tryb tłumaczenia pojawia się zwłaszcza w przypadku młodych projektów, które nie dorobiły się jeszcze integracji z np. Weblate.
Zanim zabierzemy się za jakiekolwiek dłubanie, warto sprawdzić, czy aplikacja w ogóle jest przetłumaczalna, czyli osoby ją tworzące napisały ją w sposób pozwalający na wyświetlanie różnych wersji językowych. Najprościej to zrobić rozglądając się w repozytorium kodu programu za katalogiem z plikami tłumaczeń.
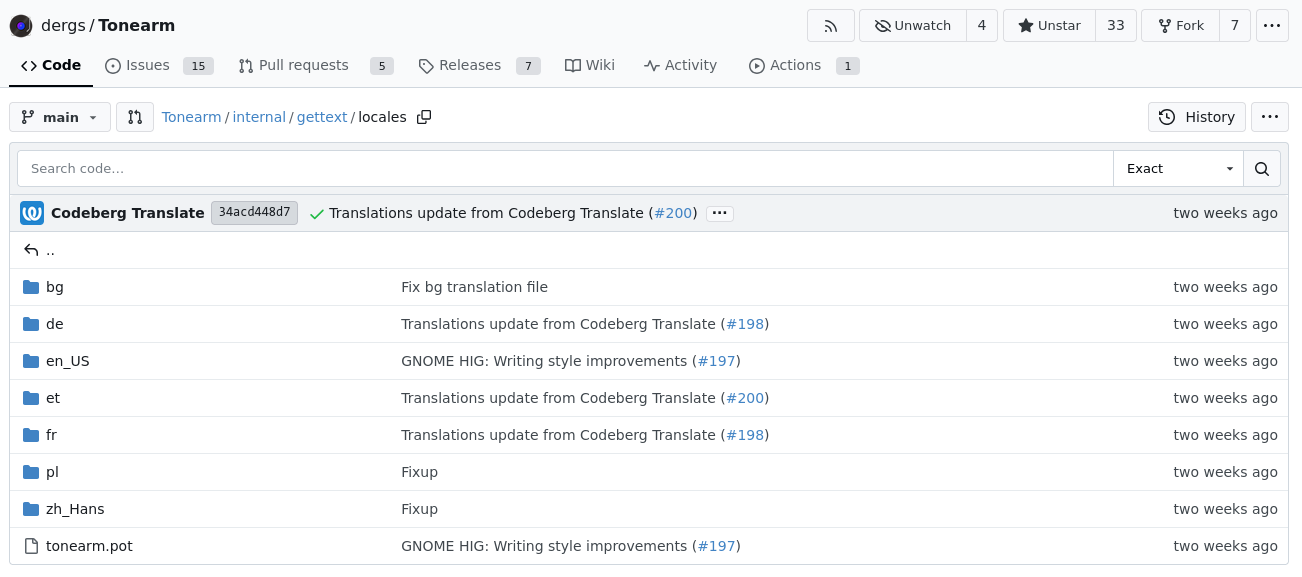
Jeżeli aplikacja korzysta z gettext, czyli najpopularniejszego systemu tworzenia wielojęzycznego oprogramowania, to katalog ten najczęściej nazywa się po prostu po, ale spotkałem też np. i18n oraz l10n.
Te dwa ostanie ciągi znaków to sprytne skróty oznaczające internationalization oraz localization, a cyferki w nich to po prostu liczba znaków między pierwszą a ostatnią literą.
Jeżeli nie znajdziecie żadnego śladu po wersjach językowych w kodzie aplikacji, to jedyne, co możecie zrobić, to skontaktowanie się z osobami ją rozwijającymi i zasugerowanie dodania obsługi wielu języków. Najprościej to zrobić przez dodanie Issue na stronie projektu, najlepiej z tagiem Enhancement.
Jeśli jednak aplikacja okaże się przekładalna, możemy brać się za tłumaczenie. Żeby to zrobić, trzeba zacząć od stworzenia własnej kopii repozytorium, czyli zrobienia forka, do czego będziemy potrzebować konta w serwisie, w którym jest rozwijany dany program (np. Codebergu, GitHubie lub GitLabie).
W tej części będę sporo posługiwać się systemem kontroli wersji o nazwie Git. Pozwala on na zapanowanie nad zmianami w kodzie i np. cofanie ich, jeżeli były błędne, a także tworzenie gałęzi, w których trwa rozwój różnych funkcjonalności i późniejsze ich scalanie. Większość rzeczy będzie można załatwić przez interfejsy WWW, ale jeżeli spróbujecie obsługi z linii poleceń, możecie uznać, że jest dużo wygodniejsza i szybsza. W poznaniu obsługi git mogą pomóc gry w rodzaju Oh My Git!, Learn Git Branching czy GitMastery.
– ![]() –
–
Jak wygląda przebieg tłumaczenia pokażę na przykładzie Blood Pressure, aplikacji, którą znalazłem niedawno na Flathub.org, po tym, jak lekarz kazał mi przez tydzień mierzyć ciśnienie i zapisywać wyniki.
Po zalogowaniu na gitlab.com i przejściu do strony projektu klikam na przycisk Fork w prawym górnym rogu, po czym wypełniam krótki formularz. Zazwyczaj po prostu dodaję litery PL do nazwy repozytorium i informację w rodzaju „Polish translation” do opisu, tym razem się rozpisałem trochę bardziej
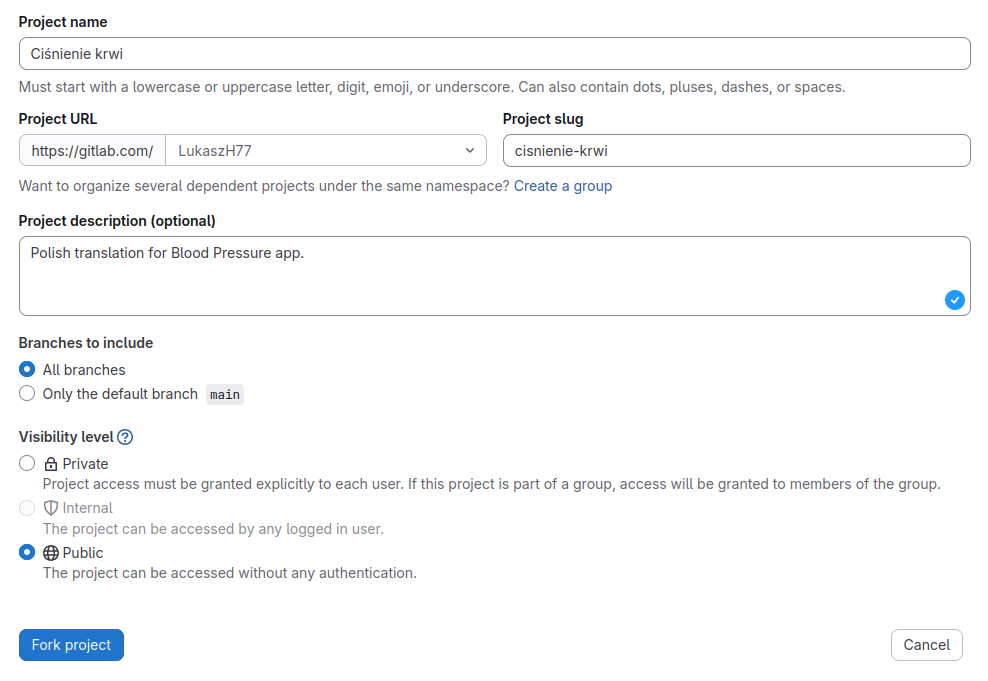
W tym momencie mam już swoje repozytorium i mogę zabierać się od razu za tłumaczenie. Mógłbym to zrobić przez edycję plików przy użyciu interfejsu GitHuba, ale wygodniej mi będzie pracować na plikach na dysku.
Jeżeli chcecie uniknąć pracy w terminalu, gdzie się tylko da, to po kliknięciu zielonego przycisku Code wybieracie opcję Download ZIP, to jednak oznacza, że stworzone i zmodyfikowane pliki będziecie trzeba wgrywać przez przeglądarkę.
Jeśli wybierzecie tryb tekstowy, to repozytorium klonuje się poleceniem git clone, po którym można podać albo adres sieciowy repozytorium w rodzaju
git clone https://gitlab.com/LukaszH77/cisnienie-krwi.gitalbo SSH
git clone git@gitlab.com:LukaszH77/cisnienie-krwi.gitTa druga opcja jest na dłuższą metę wygodniejsza, ale wymaga konfiguracji kluczy SSH w systemie oraz w serwisie z repozytorium. Ten wpis i tak będzie bardzo długi, więc nie podejmę się w nim jeszcze tłumaczenia działania i tworzenia kluczy SSH. Zarówno GitLab, jak i GitHub oraz Codeberg mają tę procedurę opisaną krok po kroku.
W końcu mamy pliki na dysku i można się przyjrzeć, z czym będziemy pracować.
Tłumaczenia przy użyciu systemu gettext opierają się na kilku rodzajach plików. POTFILES (lub POTFILES.in) zawiera listę plików źródłowych, w których znajdują się przetłumaczalne ciągi, a LINGUAS to lista języków, na które przetłumaczono aplikację. Plik z rozszerzeniem .pot (zazwyczaj nazwa_programu.pot) to wygenerowany przez gettext szablon tłumaczenia i na jego podstawie powstają pliki .po z konkretnymi wersjami językowymi (np. pl.po dla polskiego, pt_BR.po dla brazylijskiej wersji portugalskiego itd.).
W przypadku Blood Pressure nie było tego pierwszego pliku, więc postanowiłem przy okazji uzupełnić ten brak. Po jego przygotowaniu mogłem wygenerować szablon tłumaczenia poleceniem
xgettext --from-code=UTF-8 --keyword=_ --keyword=C_:1c,2 --output=po/blood-pressure.pot -f po/POTFILESParametry użyte w tym poleceniu wskazują jak jest kodowany plik, jak oznaczane w kodzie są przetłumaczalne ciągi, jak ma nazywać się tworzony plik .pot oraz z jakiej listy ma skorzystać.
Na podstawie szablonu plik z tłumaczeniem tworzy się komendą
msginit --locale=pl --input=blood-pressure.potwydanym w podkatalogu po.
--locale=pl oznacza oczywiście, że generujemy plik dla języka polskiego, a --input=blood-pressure.pot wskazuje na plik szablonu tłumaczeń.
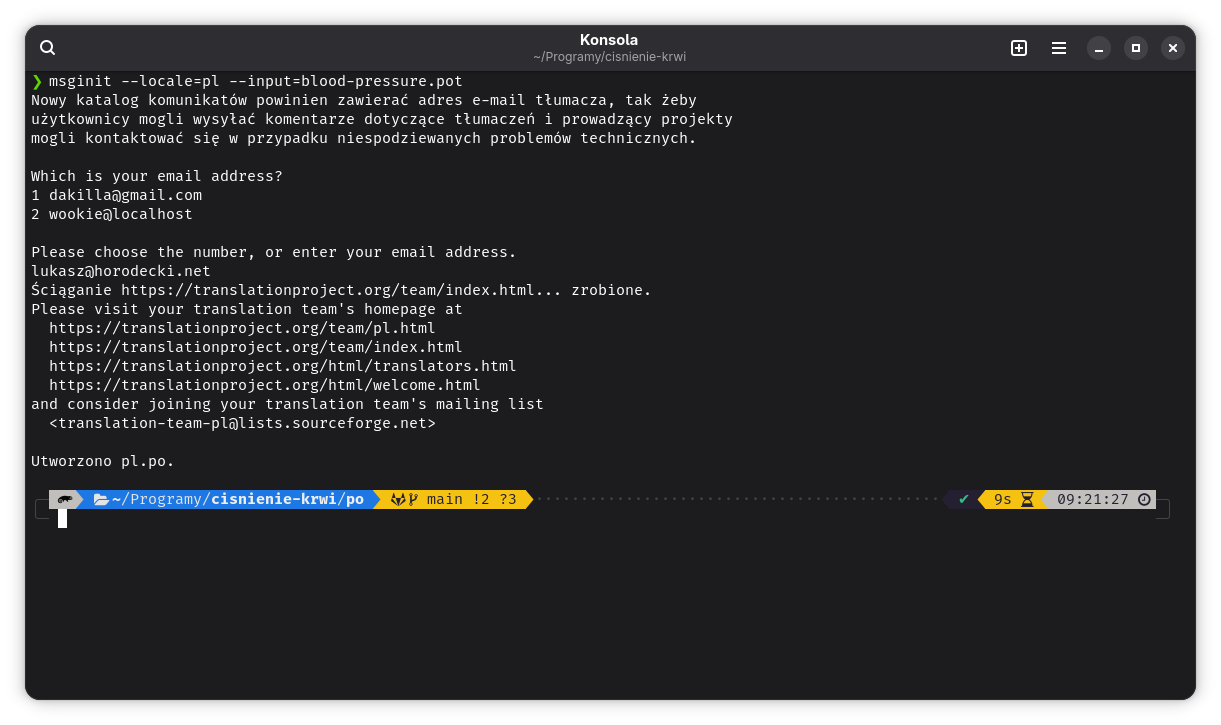
Po jej uruchomieniu zostaniemy zapytanie o adres e-mail, który ma być podany w pliku jako adres tłumacza. Po wpisaniu adresu i zatwierdzeniu powinien powstać plik pl.po, w którym będziemy wpisywali polskie tłumaczenie. Zanim się za to zabierzecie, warto najpierw otworzyć plik LINGUAS i dopisać pl w osobnym wierszu tak, żeby zachować alfabetyczną kolejność wpisów.
Tłumaczenie można załatwić w jakimkolwiek edytorze tekstu, ponieważ pliki .po są plikami tekstowymi o określonej, dość prostej strukturze. Wiersze zaczynające się od msgid zawierają oryginalny tekst, a w liniach poprzedzonych msgstr wpisujemy tłumaczenie. Każda taka para jest poprzedzona komentarzem zawierającym ścieżkę do pliku i numer linii, w której występuje ciąg, co przydaje się, gdy chcemy sprawdzić kontekst, w jakim się pojawia.
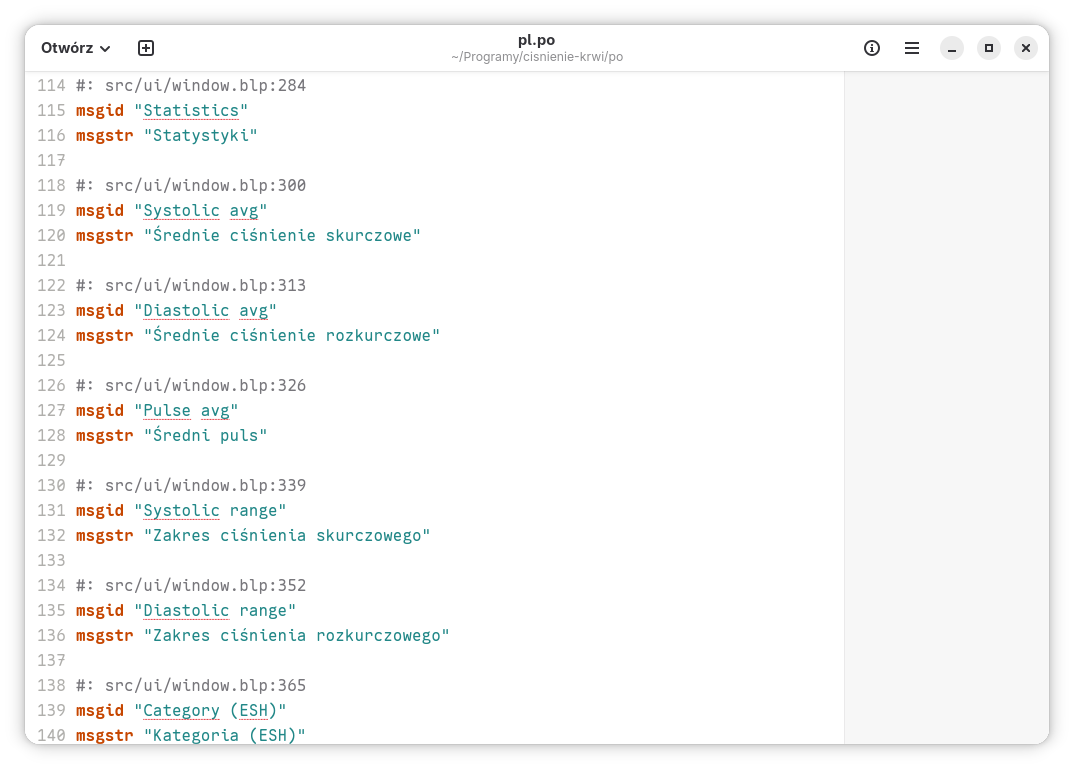
Są jednak wygodniejsze sposoby na tłumaczenie plików .po, moim ulubionym jest program Gtranslator, który powstał na potrzeby tłumaczenia GNOME (o czym więcej napiszę w dalszej części). Można go zainstalować z Flathuba.
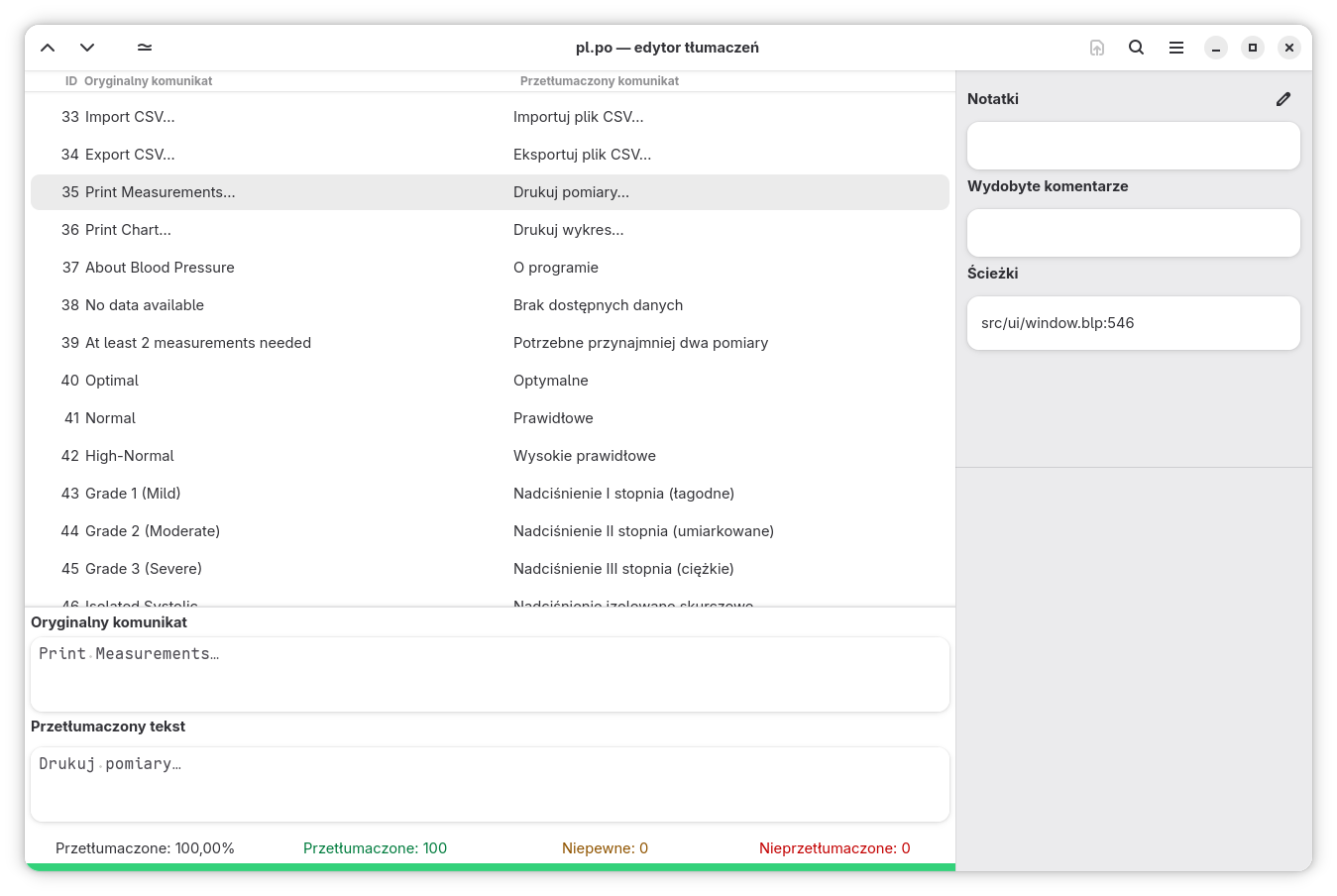
Interfejs Gtranslatora jest dość prosty. Główna część okna to lista ciągów i ich tłumaczeń, które wpisuje się w polu na dole. To, co nas interesuje w tej chwili w panelu po prawej, to pola „Wydobyte komentarze” gdzie trafiają informacje dołączone przez osoby tworzące program oraz „Ścieżki” zawierające dane o tym, w jakim pliku i wierszu występuje wybrany komunikat.
Polecam zapoznanie się ze skrótami klawiszowymi (np. Alt + -> to następny komunikat, a Alt + Page Down przechodzi do następnej nieprzetłumaczonej wiadomości), dzięki którym poruszanie się po pliku jest szybkie i wygodne.
Po przygotowaniu tłumaczenia trzeba je wrzucić do naszego repo. Jako że sklonowałem repozytorium przy użyciu git clone, to teraz mogę załatwić to wygodnie w terminalu. Najpierw przy pomocy git add dodaję po kolei pliki (całość zmian można od razu dodać komendą git add .), które utworzyłem lub zmodyfikowałem, a potem poleceniem git commit -m "Opis zmian" tworzę zatwierdzenie. Na koniec zostaje użycie git push do wypchnięcia zmian do zdalnego repozytorium na GitLabie.
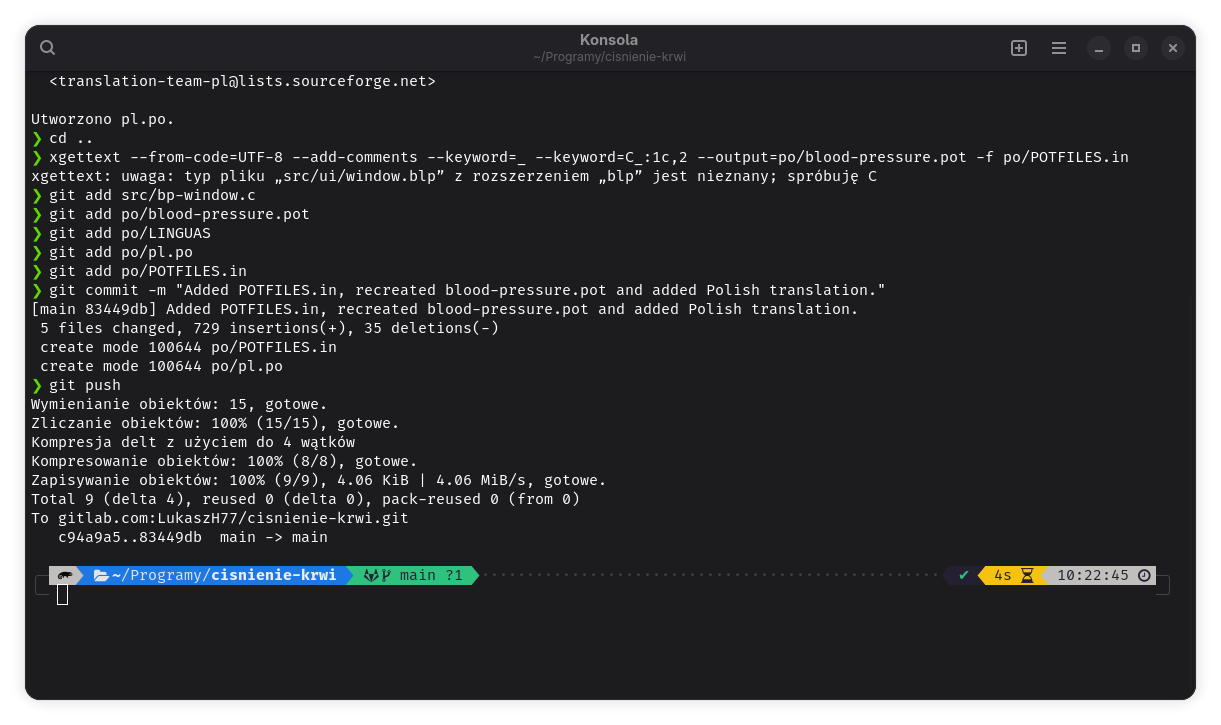
Jeżeli zamiast klonować repozytorium pobraliście tylko archiwum zip i pracowaliście na wypakowanych plikach, wszystkie te, które stworzyliście i zmieniliście, musicie teraz przez interfejs WWW wgrać do odpowiednich katalogów, co w przypadku GitLaba załatwia się nawigując po drzewie plików, a po wybraniu właściwego miejsca klikając na ikonkę plusa i wybierając pozycję „Upload file”. Oczywiście także w tym wypadku trzeba będzie podać opis zmiany.
Ostatni krok to wysłanie zmian do oryginalnego repozytorium programu. Na stronie mojego forka klikam „Create merge request” i w formularzu, który się wyświetli mogę opisać na czym polegają zmiany.
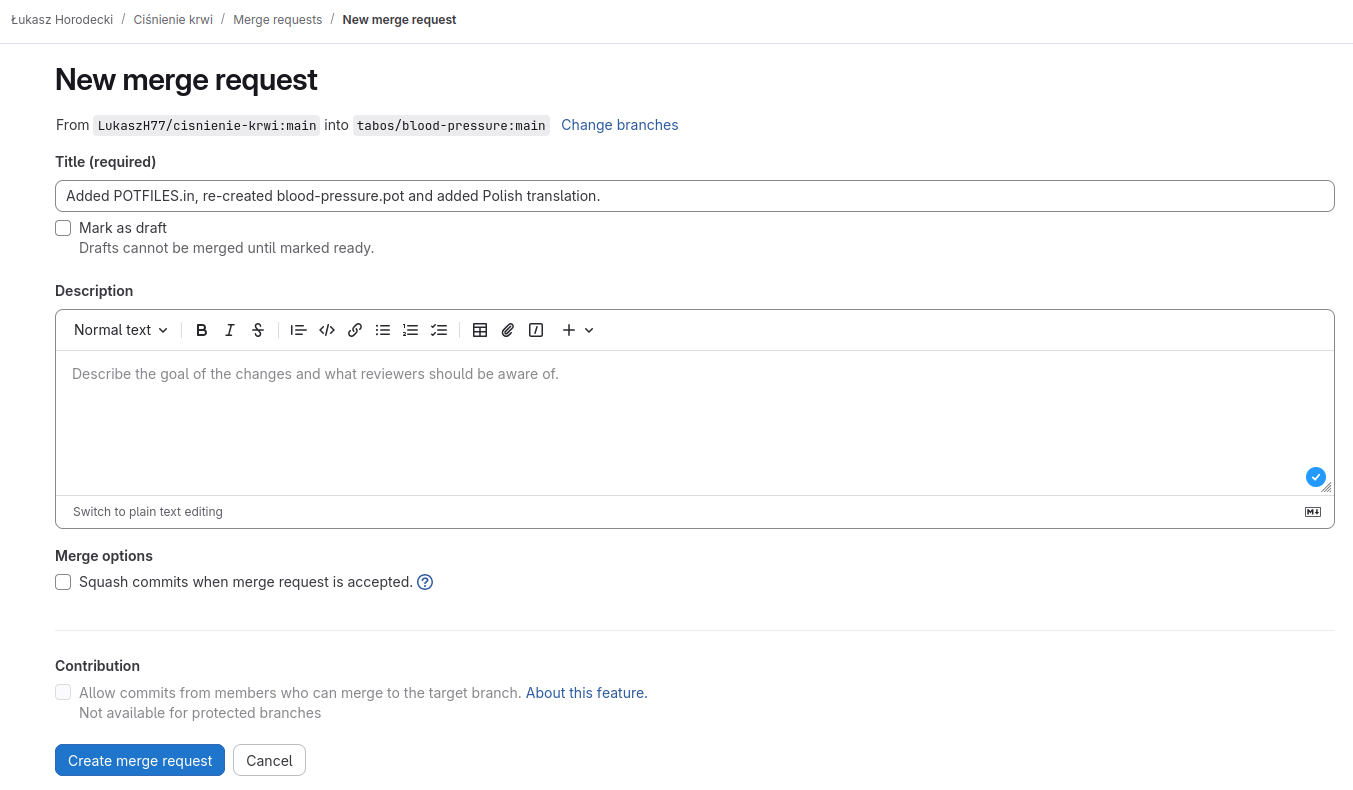
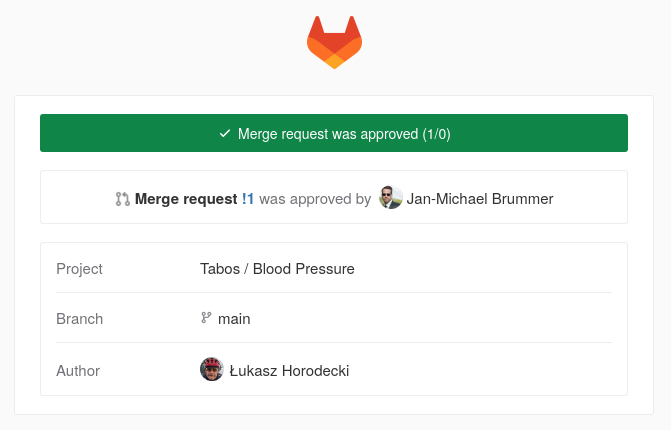
Zazwyczaj załatwiam to wcześniej, już w wiadomości dołączonej do zatwierdzenia zmienianych plików i na tej podstawie wypełniany automatycznie jest tytuł merge request, więc muszę tylko zatwierdzić wysłanie oraz zaczekać aż osoby rozwijające aplikację przejrzą moje zmiany i je zatwierdzą.
– ![]() –
–
Praca w polskim zespole GNOME
Właśnie zobaczyłem, że wpis przekroczył już 2,5k słów, więc postaram się tę ostatnią część ograniczyć do minimum.
Jak już nabierzecie trochę doświadczenia przy tłumaczeniu różnych aplikacji, to zapraszam do ekipy tłumaczącej na język polski środowisko GNOME z przylegającymi aplikacjami. Praca tutaj trochę się różni od tej, którą pokazywałem powyżej. Trzeba zacząć od założenia konta w serwisie Damned Lies, zwanego w skrócie DL. Niestety nie można zrobić tego bezpośrednio, tylko trzeba do tego użyć SSO z np. GitLaba lub GitHuba.
Następnym krokiem jest dołączenie do polskiego zespołu. Zespół jest w trakcie reorganizacji, która nałożyła się na natłok pracy przy wydaniu GNOME 50, ale nowa koordynatorka to osoba bardzo dynamiczna i sprawy idą w dobrą stronę. Dorobiliśmy się już forum na oficjalnym Discourse GNOME oraz kanału Matrix, który jest najlepszym sposobem na komunikację z resztą zespołu i zadawanie pytań związanych z tłumaczeniem.
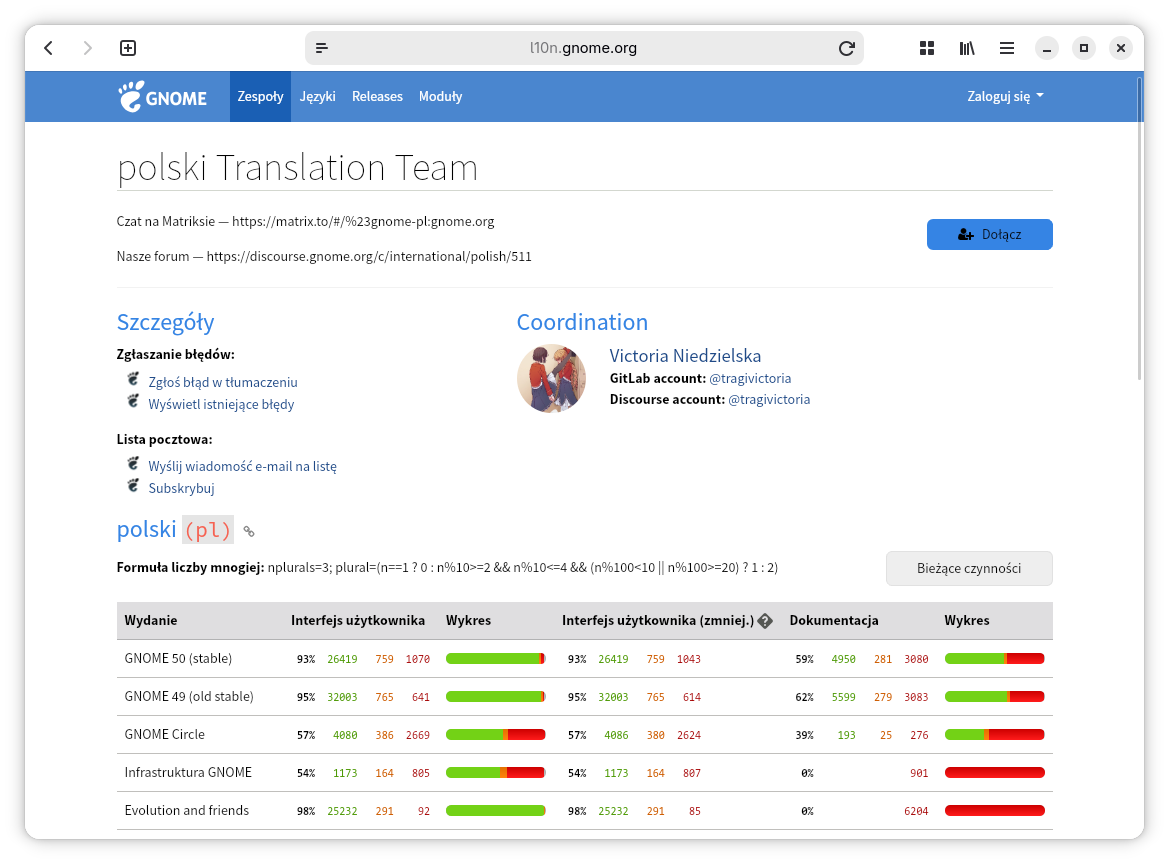
Jeżeli mamy wybrany moduł, który chcemy przetłumaczyć, pracę nad nim trzeba zacząć od zarezerwowania go do tłumaczenia poprzez formularz na stronie modułu. Możemy przy okazji dopisać komentarz, chociaż nie jest to konieczne. Potem pobieramy plik PO i zabieramy się za tłumaczenie.
Do tłumaczenia najlepiej wykorzystać Gtranslatora, którego polecałem wyżej. Można go połączyć ze swoim kontem na Damned Lies (po wpisaniu w danych profilu naszego tokenu z DL), co teoretycznie pozwoli na pobieranie i wgrywanie plików (chociaż ja wolę załatwiać to przez strony modułów, bo mogę od razu np. wyklikać rezerwację). Bardziej ciekawą możliwością jest pamięć tłumaczeń, którą można sobie zbudować na podstawie innych tłumaczeń zespołu.
Dzięki skryptowi udostępnionemu przez brazylijską ekipę przygotowałem zbiorczy plik .po z całości tłumaczeń przygotowanych dla GNOME50 i udostępniam go na swoim koncie na Codebergu. Po ściągnięciu pliku trzeba jego położenie wskazać Gtranslatorowi (Menu główne -> Zbuduj pamięć tłumaczeń). Od tej chwili w panelu po prawej będziecie mieli podpowiedzi tłumaczeń podobnych ciągów.
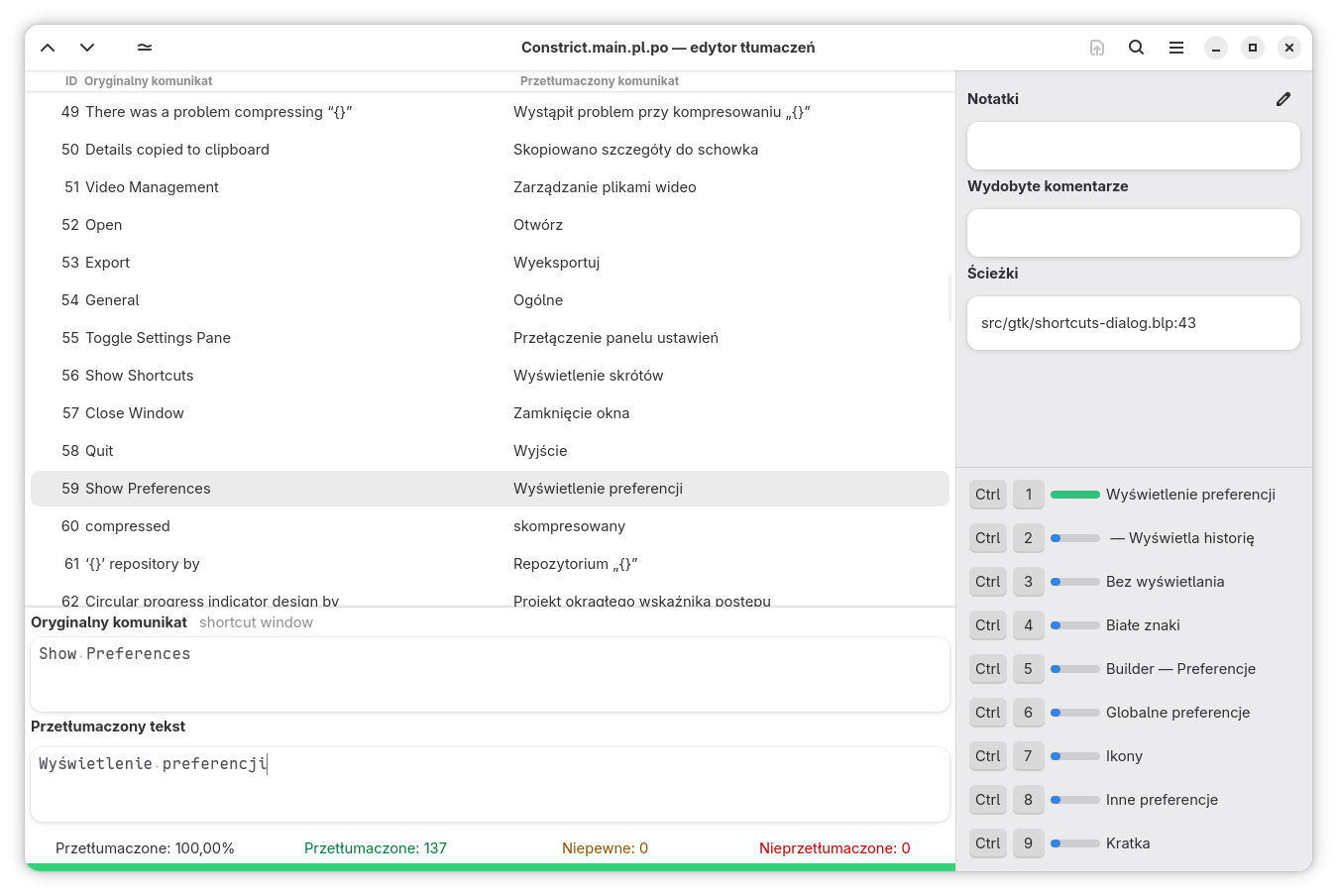
Po skończeniu tłumaczenia i zapisaniu pliku otwieramy znowu stronę modułu i w formularzu wybieramy opcję „Wyślij nowe tłumaczenie” i wgrywamy plik. Takie tłumaczenie musi zostać przejrzane przez osobę z uprawnieniami do recenzowania i jeżeli będzie poprawne, to zostanie zatwierdzone i wypchnięte do repozytorium.
Może się zdarzyć, że zamiast tego dostaniemy recenzję z informacjami, które ciągi mają błędy i jak je należy poprawić tak, by spełniały standardy zespołu. Aby ograniczyć prawdopodobieństwo poprawek, warto pamiętać m.in. o tym, że po każdym jednoliterowym spójniku (a, i, o, u, w, z) powinna znaleźć się niełamliwa spacja (wstawiana za pomocą Prawy alt + Spacja), dzięki czemu przy dzieleniu tekstu na wiersze, na ich końcu nie będą wisieć pojedyncze litery.
Zespół planuje przygotowanie wytycznych dotyczących tłumaczenia (np. preferowanych form gramatycznych dla różnych elementów interfejsu oraz używania form neutralnych płciowo) i gdy będą gotowe, to je tutaj podczepię, ale na razie warto przyjrzeć się temu, jak wyglądają dotychczasowe tłumaczenia, a w razie wątpliwości zapytać w naszym pokoju Matrix.
– ![]() –
–
Myślę, że to najwyższy czas, żeby zakończyć ten wpis i cały cykl. Mam nadzieję, że pokazując tyle różnych sposobów na zaangażowanie się w FOSS uda mi się namówić do tego chociaż jedną osobę.
Jeżeli macie jakieś pytania dotyczące poruszonych w tych wpisach zagadnień, lub uważacie, że podane przeze mnie informacje wymagają uzupełnienia, a być może są błędne, to proszę dajcie znać w komentarzach. Z chęcią poznam wasze zdanie i uzupełnię swoje braki w wiedzy.

Dodaj komentarz